Understanding Object Storage: A Guide for Research Software Development

Understanding Object Storage: A Guide for Research Software Development
These blog posts are intended to provide software tips, concepts, and tools geared towards helping you achieve your goals. Views expressed in the content belong to the content creators and not the organization, its affiliates, or employees. If you have any questions or suggestions for blog posts, please don’t hesitate to reach out!
Introduction
Managing large-scale scientific data is a defining challenge of modern research. With datasets regularly exceeding gigabytes—or even terabytes—in size, researchers require scalable, cost-effective, and reliable storage infrastructure.
Object storage offers a flexible alternative to traditional filesystems. It supports high-throughput access, structured metadata, and distributed scaling, making it a foundational tool in research computing, reproducible science, and FAIR data practices.
In this article, we’ll trace the evolution of object storage (also sometimes referred to as “S3”, “storage buckets”, or “object stores”), explain its design principles, survey current platforms, and walk through a hands-on example using the open-source MinIO tool.
A brief history of object storage
Traditional storage systems relied on block storage (used by hard drives) and file storage (used by operating systems). While effective for early computing, these models struggled to scale with the demands of scientific data and cloud-native applications.
Object storage originated in the research community to address these challenges. In the late 1990s, the NASD project at Carnegie Mellon and HP Labs introduced the idea of storing data as self-contained objects with rich metadata—decoupling data access from file hierarchies (Gibson et al., 1998).
In the early 2000s, the open-source Ceph project (from UCSC) introduced the now-famous CRUSH algorithm to distribute data without centralized metadata bottlenecks (Weil et al., 2006).
Amazon S3 brought these ideas to a global audience in 2006, offering a scalable, HTTP-accessible object store with an API-driven model that became a standard for cloud and scientific applications (Amazon S3 launch blog post).
Unlike file systems, object stores provide:
- A flat namespace with key-based access
- Rich, customizable metadata
- Scalable, distributed architecture
These qualities make object storage essential for managing large, unstructured, and reproducible scientific datasets.
Why use object storage for research?
Object storage is not just a buzzword. It enables capabilities increasingly vital to modern research:
- Scalability: Stores billions of files with virtually no performance degradation.
- Flexibility: Ideal for unstructured data (images, JSON, audio, NetCDF, Parquet, etc.).
- Metadata-rich: Stores metadata alongside objects, useful for provenance, reproducibility, and FAIR data principles (Wilkinson et al., 2016).
- Cloud-native: Compatible with public cloud platforms and on-premises deployments.
- HTTP-accessible: Allows sharing, versioning, and integration with APIs and remote workflows.
Traditionally seen as a passive place to “put files,” object storage is often now being used as a primary data substrate—functioning more like a database than just a dumping ground. This shift aligns closely with principles from the Composable Data Management System Manifesto (Pedreira et. al, 2023), which advocates for modular, interoperable, and storage-agnostic data infrastructure.
Generally, consider use cases like:
- Long-term archiving of large-scale microscopy datasets.
- Sharing reproducible analysis results using structured metadata.
- Automating pipelines that read and write from shared storage
In research, where data integrity, sharing, and sustainability are paramount, object storage provides a modern backbone.
Common platforms and ecosystem
Below are some popular object storage platforms used in research and industry:
| Platform | Description | Type |
|---|---|---|
| Amazon S3 | The original commercial object store. | Commercial |
| Google Cloud Storage | Integrated with Google Cloud ecosystem. | Commercial |
| Azure Blob Storage | Microsoft’s cloud object store. | Commercial |
| MinIO | High-performance, S3-compatible OSS. | Open Source |
| Ceph | Distributed object (and block/file) system. | Open Source |
| Wasabi | Cost-effective S3-compatible storage. | Commercial |
| OpenStack Swift | Open-source cloud platform component. | Open Source |
In academic environments, MinIO and Ceph are frequently used for institutional deployments that must remain on-premises or comply with specific data governance needs.
How object storage works
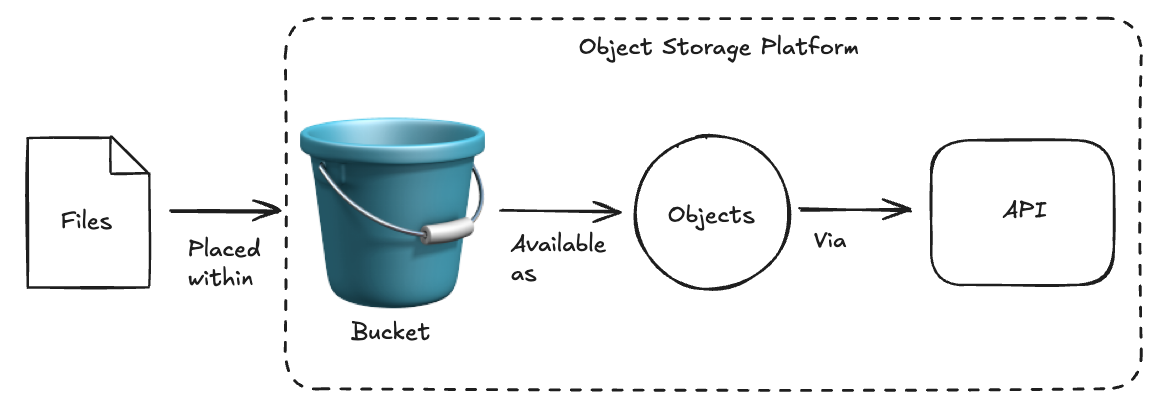
Here are the core principles of object storage to help conceptualize common terms and how it works.
- Flat Namespace: No folder hierarchies; everything is accessed via a unique object key (similar to a URL path). Folders are typically simulated with “/” slashes to help unify how one may reference objects in correspondence with a filesystem.
- Objects: Each unit of data includes the content, metadata, and a unique identifier (key).
- Buckets: Logical containers for grouping objects (like folders, but flat). Generally a bucket is associated with one project.
- APIs: Most object stores use HTTP REST APIs, often based on the Amazon S3 API.
- Versioning and Lifecycle: Objects can be versioned and automatically expired or archived.
- Event Notification: Some systems emit events (e.g., via webhooks or queues) when new data is written—ideal for automation pipelines.
Demo: Using MinIO for object storage data

Let’s walk through how to use MinIO to create and interact with object storage on your local system. MinIO is lightweight, open source, and provides an S3-compatible interface, making it nice for development and reproducible demos.
Step 1: Install MinIO
You can install MinIO locally via Docker:
docker run -p 9000:9000 -p 9001:9001 \
-e "MINIO_ROOT_USER=minioadmin" \
-e "MINIO_ROOT_PASSWORD=minioadmin" \
quay.io/minio/minio server /data --console-address ":9001"
Access the web UI at http://localhost:9001 using the above credentials.
Step 2: Upload a file
You can interact with MinIO using the official mc client:
# install client
brew install minio/stable/mc # or use curl/wget for Linux
# configure client
mc alias set local http://localhost:9000 minioadmin minioadmin
# create a bucket
mc mb local/research-data
# create a file
echo "1,2,3" > dataset.csv
# upload a file
mc cp dataset.csv local/research-data
Step 3: Access via Python

You can also use the official MinIO Python client to interact with your object storage server:
pip install minio
Then, use the client to connect and list objects:
from minio import Minio
# Initialize client
client = Minio(
"localhost:9000",
access_key="minioadmin",
secret_key="minioadmin",
secure=False # Use True if running over HTTPS
)
# List objects in a bucket
for obj in client.list_objects("research-data"):
print(obj.object_name)
This approach is lightweight, straightforward, and ideal for working directly with MinIO in local or institutional deployments.
Streaming Data from Object Storage with MinIO, Pandas, Polars, or DuckDB

In composable data workflows, streaming data directly from object storage is increasingly common. Instead of downloading full files to local disk, tools like Pandas and DuckDB can read from object storage streams—reducing I/O overhead and enabling efficient in situ analytics. Tools like fsspec can abstract access across many storage backends—including S3 and GCS—making it easier to build storage-agnostic workflows.
Example: Streaming a CSV into Pandas
import pandas as pd
# Stream data from the S3 API (MinIO) into a Pandas DataFrame
df_s3 = pd.read_csv(
"s3://my-bucket/data.csv",
storage_options={
"key": "minioadmin",
"secret": "minioadmin",
"client_kwargs": {"endpoint_url": "http://localhost:9000"},
}
)
Example: Streaming a CSV into Polars
import polars as pl
# Stream data from the S3 API (MinIO) into a Polars DataFrame
df_s3 = pl.read_csv(
"s3://my-bucket/data.csv",
storage_options={
"key": "minioadmin",
"secret": "minioadmin",
"client_kwargs": {"endpoint_url": "http://localhost:9000"},
}
)
Example: Streaming a CSV into DuckDB
import duckdb
with duckdb.connect() as ddb:
# Stream data from the S3 API (MinIO)
# from DuckDB into Pandas DataFrame
df = ddb.execute(
f"""
/* install httpfs for duckdb */
INSTALL httpfs;
LOAD httpfs;
/* add a custom secret for access to endpoint */
CREATE SECRET (
TYPE s3,
KEY_ID 'minioadmin',
SECRET 'minioadmin',
ENDPOINT 'localhost:9000'
);
/* perform selection on the file */
SELECT * FROM read_csv('s3://my-bucket/data.csv');
"""
).df()
S3-compatible object storage case study: Dell PowerScale (Isilon)

Some research institutions like the University of Colorado Anschutz have adopted Dell PowerScale (Isilon) for file and object storage (CU Anschutz Storage Options). This adds some convenience due to its ability to serve both traditional file-based workloads (i.e. filemounts) and modern S3-API based pipelines like those described above.
Isilon allows researchers to treat data stored on the NAS as S3-compatible objects, enabling seamless integration with cloud-native tools and streaming workflows—even in strictly on-premises environments.
💸 Cost savings: Isilon object storage vs. cloud storage (AWS/GCP)
Cloud object storage platforms like AWS S3 and Google Cloud Storage (GCS) offer great scalability, but they often come with ongoing costs that grow with usage, especially due to egress fees (i.e., data leaving the cloud) or operation charges (when you make changes to objects).
In contrast, on-premises object storage systems—like Dell Isilon—can provide substantial long-term savings for research institutions that already maintain storage infrastructure. Similar to cloud-provider object storage systems, you can still use S3-like API’s through tools like MinIO with Isilon.
💾 Storage cost comparison (approximate, per GB per month)
Object storage providers generally charge a flat fee for the amount of data stored within their platform by month. Cloud providers typically charge varying rates by “storage class” which stipulate how frequently you will access the data (lower cost storage classes often have higher egress or outgoing tranfer costs). For the sake of an example below we use “standard” or default storage classes below. See below for some examples.
| Storage Tier | Storage Cost (USD/GB/mo) | Notes |
|---|---|---|
| Dell Isilon | $0.016 | Based on CU Anschutz Rates |
| AWS S3 Standard (AWS S3) | $0.023 | S3 Standard - Pricing Link |
| Google Cloud Storage (GCS) | $0.020 | Standard storage - Pricing Link |
📤 Data transfer cost (Egress)
Object storage providers often charge for “egress”, or data transfers to a location outside their platforms. These charges may seem small at first but can add up over time. It’s also important to note “ingress”, or data transferred into an object storage provider’s bucket, may also have distinct cost implications (these are often less than egress). Note: Isilon at CU Anschutz is currently limited to virtual private network (VPN) or campus-based networks for egress and ingress.
| Provider | Egress (Download) Cost Per GB | Notes |
|---|---|---|
| Dell Isilon | $0.00 | No per-byte charge for transfers for CU Anschutz Rates |
| AWS S3 | $0.09 | First 10 TB per month after 100GB free tier Pricing Link |
| GCS | $0.12 | First TB per month Pricing Link |
An example scenario
Some of the above numbers are difficult to contextualize without an example scenario. Consider an example scenario where we have 500 GB stored for 6 months and where we download that 500 GB once per month. Keep in mind these are estimations and don’t include additional other charges from cloud providers, tax, and other considerations.
| Provider | Calculation | Total |
|---|---|---|
| Dell Isilon | $0.016 * 500 GB * 6 Months (no additional cost for egress) |
$48.00 |
| AWS S3 | ($0.023 * 500 GB * 6 Months) + ($0.09 * 400 GB * 6 Months) |
$285.00 |
| GCS | ($0.020 * 500 GB * 6 Months) + ($0.12 * 500 GB * 6 Months) |
$420.00 |
Conclusion
Object storage is a foundational technology for modern research computing. It allows research teams to scale data access, enable metadata-rich reproducibility, and bridge the gap between local experimentation and cloud workflows.
By learning how to use tools like MinIO and understanding the object storage model, research software developers can design more robust, future-proof, and FAIR-aligned systems for handling scientific data.
“Data is a precious thing and will last longer than the systems themselves.” - Tim Berners-Lee
Further Reading
- Wilkinson, M. D., et al. (2016). The FAIR Guiding Principles for scientific data management and stewardship.
- MinIO Documentation: https://min.io/docs
- AWS S3 API Reference: https://docs.aws.amazon.com/AmazonS3/latest/API/Welcome.html
- GO FAIR Initiative: https://www.go-fair.org/