Leveraging Kùzu and Cypher for Advanced Data Analysis

Leveraging Kùzu and Cypher for Advanced Data Analysis
These blog posts are intended to provide software tips, concepts, and tools geared towards helping you achieve your goals. Views expressed in the content belong to the content creators and not the organization, its affiliates, or employees. If you have any questions or suggestions for blog posts, please don’t hesitate to reach out!
Introduction
Graph databases can offer a more natural and intuitive way to model and explore relationships within data. In this post, we’ll dive into the world of graph databases, focusing on Kùzu, an embedded graph database and query engine for a number of languages, and Cypher, a powerful query language designed for graph data. We’ll explore how these tools can transform your data management and analysis workflows, provide insights into their capabilities, and discuss when it might be more appropriate to use server-based solutions. Whether you’re a research software developer looking to integrate advanced graph processing into your applications or simply curious about the benefits of graph databases, this guide will equip you with the knowledge to harness the full potential of graph data.
Tabular Data
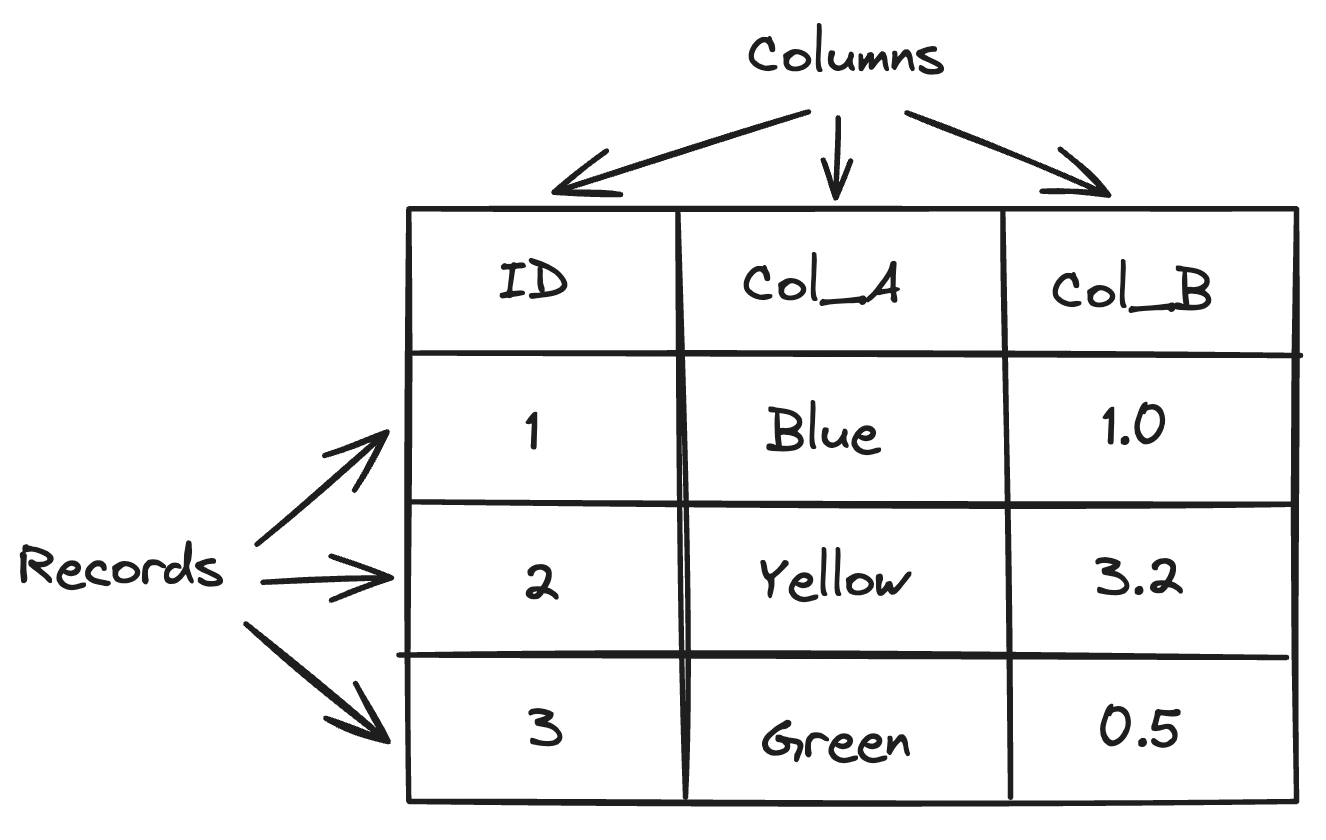
Data are often stored in a table, or tabular format, where information is organized into rows and columns. Each row represents a single record and each column represents attributes of that record. Tables are particularly effective for storing and querying large volumes of data with a fixed set of columns and data types. Despite its versatility, tabular data can become cumbersome when dealing with complex relationships and interconnected data, where a graph-based approach might be more suitable.
Graph Data
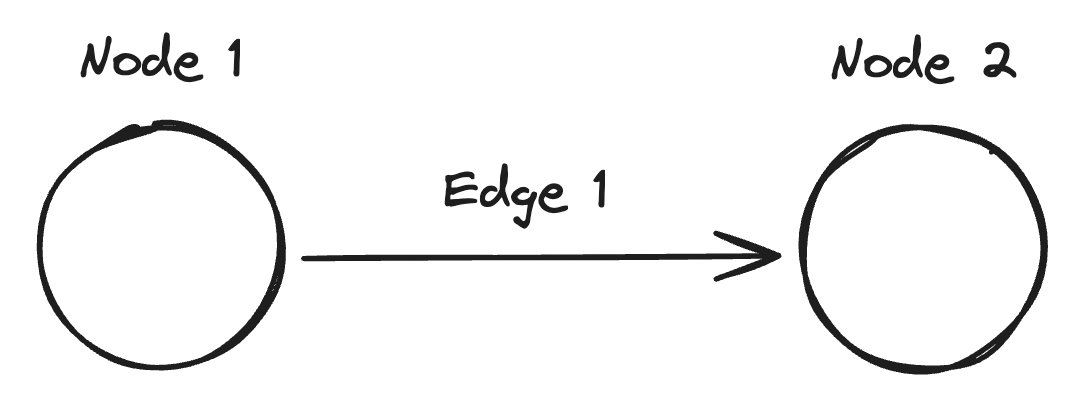
Graph data represents information in the form of nodes (also called vertices) and edges (connections between nodes). This structure is useful for modeling complex relationships and interconnected data, such as social networks, biological networks, and transportation systems. Unlike tabular data, which is often “flattened” (treating multidimensional data as singular columns) and often rigid (requiring all new data to conform to a specific schema), graph data allows for more flexible and dynamic representations.
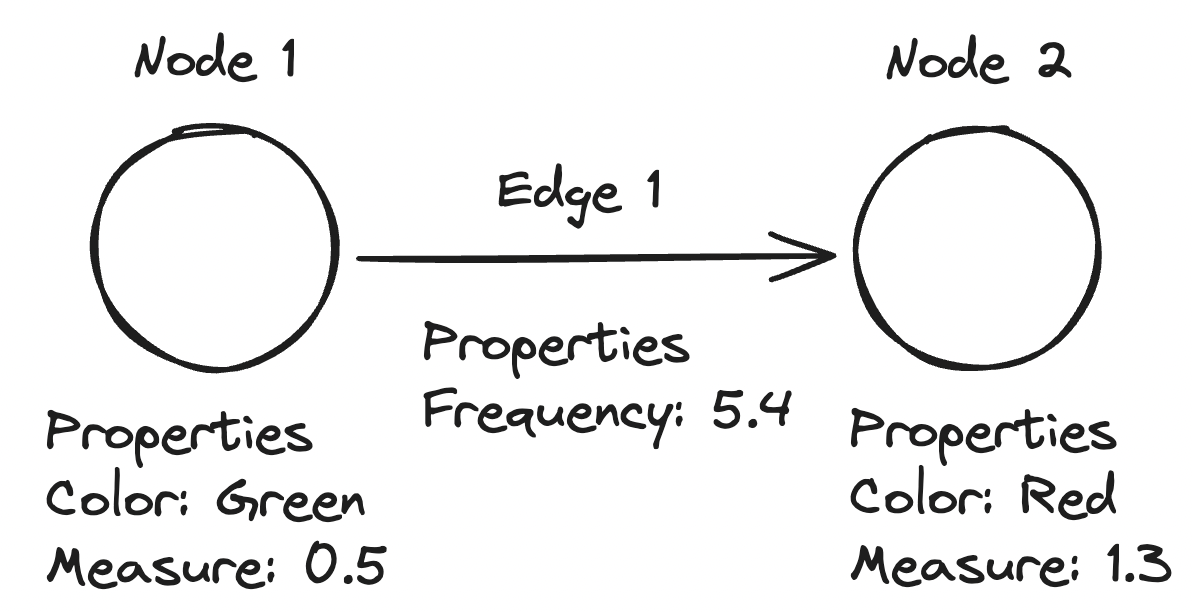
Nodes and edges act like different kinds of tabular records within the context of graphs. Nodes and edges can also have properties (attributes) which further provide description to a graph. Properties are akin to columns of a particular record in tabular formats which help describe a certain record (or node). Graph data models are particularly useful for exploring connections, performing path analysis, and uncovering patterns that may require more transformation in tabular formats.
Graph Databases
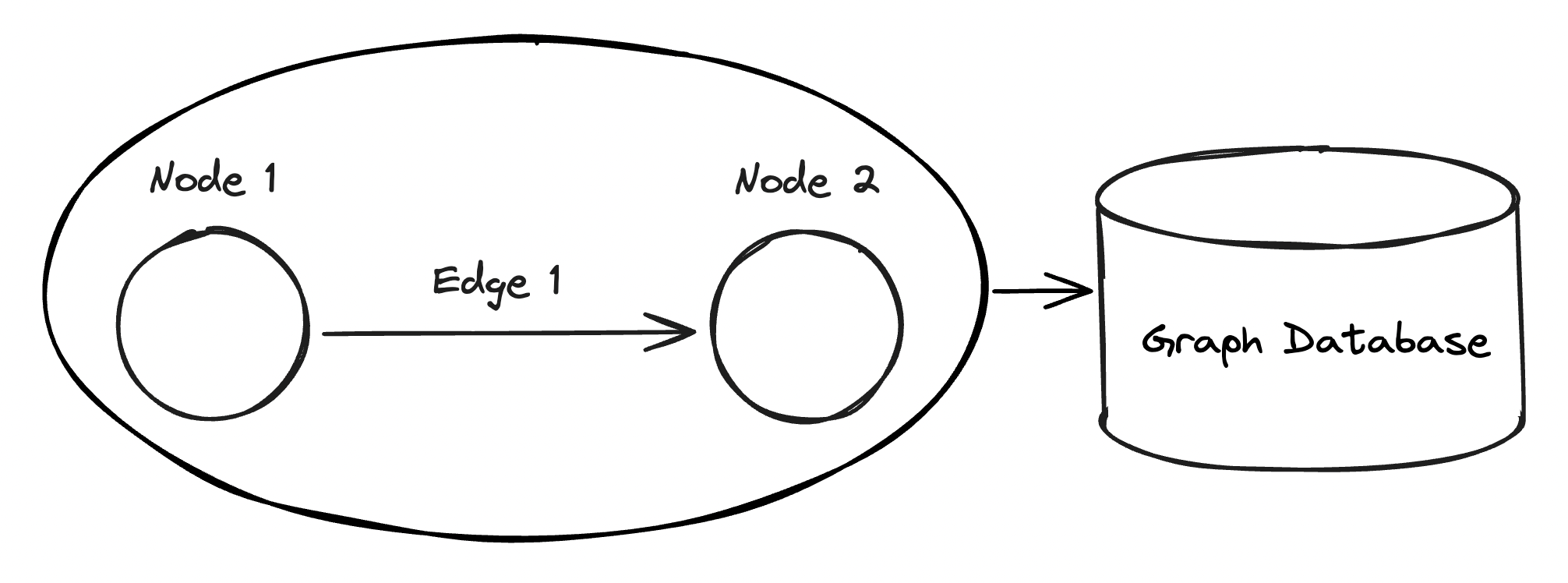
Graph databases are specialized databases designed to store, query, and manage graph data efficiently. They use graph structures for semantic queries, with nodes, edges, and properties being stored directly in the database. Unlike traditional relational databases that use tables, graph databases leverage the natural relationships in the data, allowing for faster retrieval and sometimes more intuitive querying of interconnected information. This makes them ideal for applications involving complex relationships, such as social networks, supply chain management, and knowledge graphs. Graph databases support various query languages and algorithms optimized for traversing and analyzing graph structures.
Graph Database Querying
Graph database querying involves using specialized query languages to retrieve and manipulate graph data. Unlike SQL, which often is used for tabular databases, graph databases use languages like Cypher, Gremlin, and SPARQL, which are designed to handle graph-specific operations. These languages allow users to perform complex queries that traverse the graph, find paths between nodes, filter based on properties, and analyze relationships. Querying in graph databases can be highly efficient due to their ability to leverage the inherent structure of the graph, enabling fast execution of complex queries that would be cumbersome and slow in a relational database.
Cypher Query Language
MATCH (p:Person {name: 'Alice'})-[:FRIEND]->(friend)
RETURN friend.name, friend.age
This query finds nodes labeled “Person” with the name “Alice” and returns the names and ages of nodes connected to Alice by a “FRIEND” relationship.
Cypher is a powerful, declarative graph query language designed specifically for querying and updating graph databases.
Originally developed for Neo4j (one of the most popular graph databases), it is known for its expressive and intuitive syntax that makes it easy to work with graph data.
Cypher allows users to perform complex queries using simple and readable patterns that resemble ASCII art, making it accessible to both developers and data scientists.
It supports a wide range of operations, including pattern matching, filtering, aggregation, and graph traversal, enabling efficient exploration and manipulation of graph structures.
For example, a basic Cypher query to find all nodes connected by a “FRIEND” relationship might look like this: MATCH (a)-[:FRIEND]->(b) RETURN a, b, which finds and returns pairs of nodes a and b where a is connected to b by a “FRIEND” relationship.
Kùzu
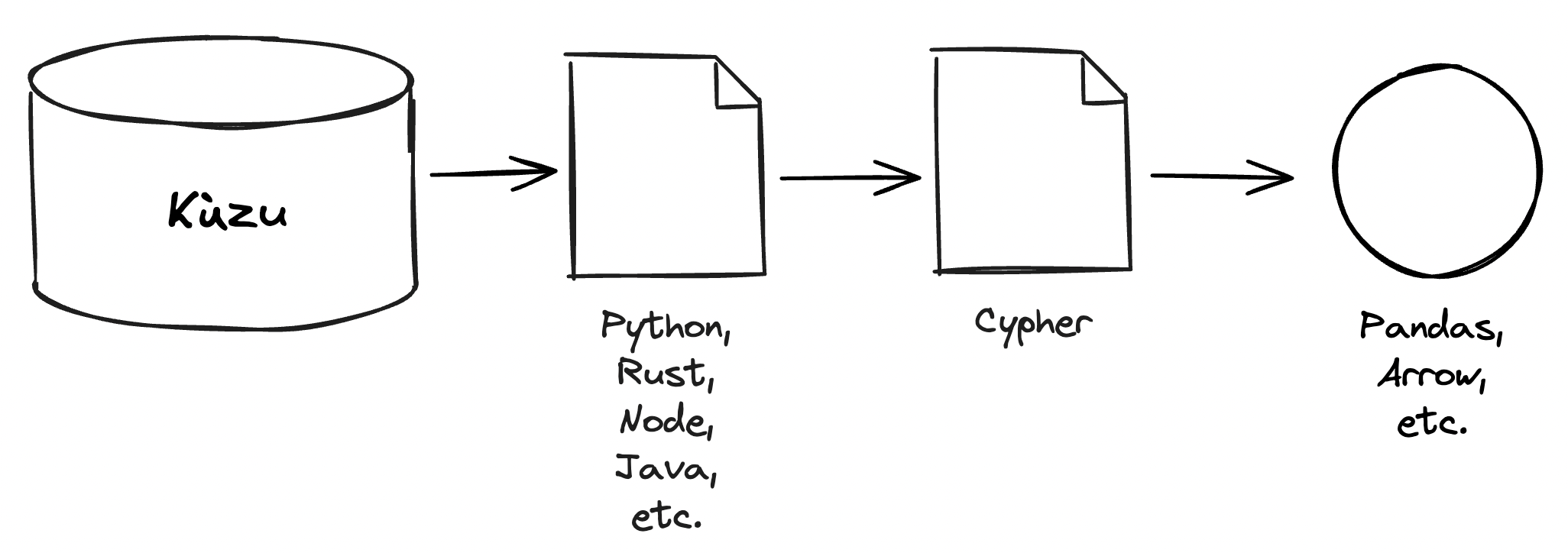
Kùzu is an embedded graph database and query engine designed to integrate seamlessly with Python, Rust, Node, C/C++, or Java software. Kùzu is optimized for high performance and can handle complex graph queries with ease. Querying graphs in Kùzu is performed using the Cypher syntax, providing transferrability of queries in multiple programming languages. Kùzu also provides direct integration with export formats that allow for efficient data analysis or processing such as Pandas and Arrow. Kùzu is particularly suitable for software developers who need to integrate graph database capabilities into their projects without the overhead of managing a separate database server.
Tabular and Graph Data Interoperation

Tabular data and graph data can sometimes be used in tandem in order to achieve software goals (one isn’t necessaryily better than the other or supposed to be used in isolation). For example, Kùzu offers both data import and export to tabular formats to help with conversion and storage outside of a graph database. This is especially helpful when working with tabular data as an input, when trying to iterate over large datasets in smaller chunks, or building integration paths to other pieces of software which aren’t Kùzu or graph data compatible.
Kùzu Tabular Data Imports
# portions of this content referenced
# with modifications from:
# https://docs.kuzudb.com/import/parquet/
import pandas as pd
import kuzu
# create parquet-based data for import into kuzu
pd.DataFrame(
{"name": ["Adam", "Adam", "Karissa", "Zhang"],
"age": [30, 40, 50, 25]}
).to_parquet("user.parquet")
pd.DataFrame(
{
"from": ["Adam", "Adam", "Karissa", "Zhang"],
"to": ["Karissa", "Zhang", "Zhang", "Noura"],
"since": [2020, 2020, 2021, 2022],
}
).to_parquet("follows.parquet")
# form a kuzu database connection
db = kuzu.Database("./test")
conn = kuzu.Connection(db)
# use wildcard-based copy in case of multiple files
# copy node data
conn.execute('COPY User FROM "user*.parquet";')
# copy edge data
conn.execute('COPY Follows FROM "follows*.Parquet";')
df = conn.execute(
"""MATCH (a:User)-[f:Follows]->(b:User)
RETURN a.name, b.name, f.since;"""
).get_as_df()
One way to create graphs within Kùzu is to import data from tabular datasets. Kùzu provides functionality to convert tabular data from CSV, Parquet, or NumPy files into a graph. This process enables seamless integration of tabular data sources into the graph database, providing the benefits of graph-based querying and analysis while leveraging the familiar structure and benefits of tabular data.
Kùzu Data Results and Exports
# portions of this content referenced
# with modifications from:
# https://kuzudb.com/api-docs/python/kuzu.html
import kuzu
# form a kuzu database connection
db = kuzu.Database("./test")
conn = kuzu.Connection(db)
query = "MATCH (u:User) RETURN u.name, u.age;"
# run query and return Pandas DataFrame
pd_df = conn.execute(query).get_as_df()
# run query and return Polars DataFrame
pl_df = conn.execute(query).get_as_pl()
# run query and return PyArrow Table
arrow_tbl = conn.execute(query).get_as_arrow()
# run query and return PyTorch Geometric Data
pyg_d = conn.execute(query).get_as_torch_geometric()
# run query within COPY to export directly to file
conn.execute("COPY (MATCH (u:User) return u.*) TO 'user.parquet';")
Kùzu also is flexible when it comes to receiving data from Cypher queries. After performing a query you have the option to use a number of methods to automatically convert into various in-memory data formats, for example, Pandas DataFrames, Polars DataFrames, PyTorch Geometric (PyG) Data, or PyArrow Tables. There are also options to export data directly to CSV or Parquet files for times where file-based data is preferred.
Concluding Thoughts
Kùzu, with its seamless integration into Python environments and efficient handling of graph data, presents a compelling solution for developers seeking embedded graph database capabilities. Its ability to transform and query tabular data into rich graph structures opens up new possibilities for data analysis and application development. However, it’s important to consider the scale and specific needs of your project when choosing between Kùzu and more robust server-based solutions like Neo4j. By leveraging the right tool for the right job, whether it’s Kùzu for lightweight embedded applications or a server-based database for enterprise-scale operations, developers can unlock the full potential of graph data. Embracing these technologies allows for deeper insights, more complex data relationships, and ultimately, more powerful and efficient applications.